Полуавтоматически чистим семъядро интересующего нас сайта, чтобы не тратить затем время на анализ бесперспективных запросов. Часть шагов необязательны или взаимозаменяемы, выполняйте все действия осмысленно и корректируйте тактику от задачи.
Это инструкция для начинающих специалистов поисковой оптимизации. Если вы попали сюда не по прямой ссылке, читайте с осторожностью
1. Собираем частотные запросы из топа
Допустим, мы хотим расширить контент-план по туристической тематике. Нашли сайт журнала «Вокруг света»: https://www.vokrugsveta.ru/.
Открываем отчет по домену «Кейсо» в «Яндексе», переходим в раздел «Ключевые фразы».
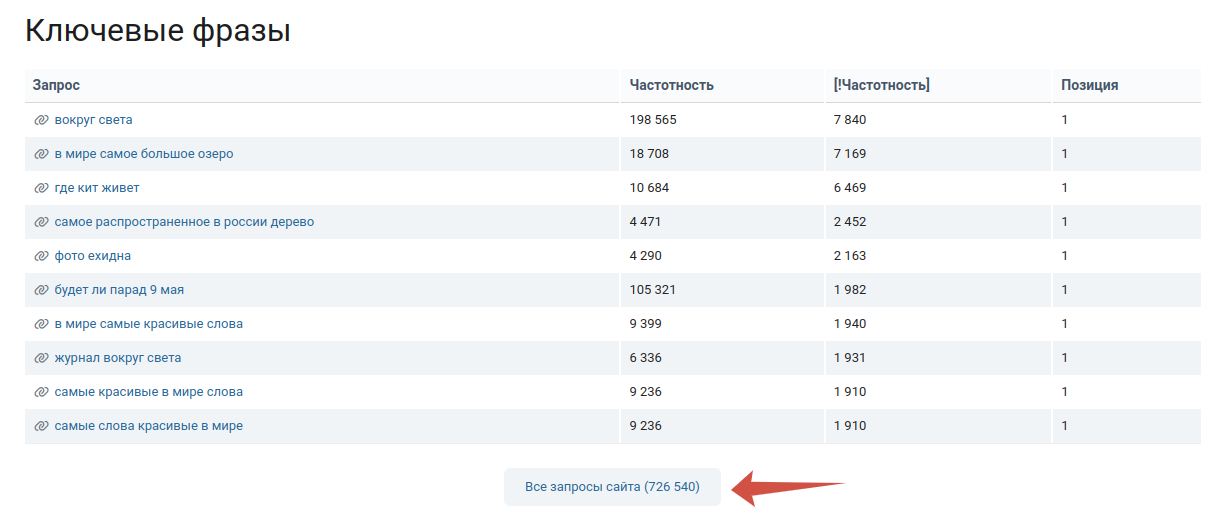
Изначально доступно 700 тысяч запросов, но с таким объемом работать невозможно. Сокращаем число строк, настраивая два фильтра: минимальная точная частотность запроса и максимальная позиция сайта по ключу.

Какие параметры указать и сколько строк оставить — решайте сами. Если конкурент большой и сочный, а мы его даже не щупали, берите с запасом.
Впрочем, минимальную позицию берите не больше пяти включительно, иначе будет много мусорных ВЧ-запросов в духе «вк», «госулуги» и прочее. Частотность подкручивайте постепенно, пока не достигнете необходимого объема запросов.
Скачайте итоговые данные в виде csv и загрузите их в «Гугль Таблицы».
2. Выделяем маркерный запрос страницы
Большинство SEO-специалистов далее удалят дубли и кластеризуют, но у нас быстрый анализ для контент-плана СМИ. 50 запросов из одного кластера нам пока не интересны, лучше пусть будет 50 маркерных запросов для разных статей.
Если же вам по душе классический подход со сбором кластеров, пропустите этот шаг, но обязательно выполните шестой.
Берем табличку и добавляем в нее фильтры, для этого нажимаем на соответствующую иконку на панели инструментов.
Для удобства расширьте столбцы A, B и E, будем работать с ними. Отсортируйте «Точную частотность» (столбец E) по убыванию.
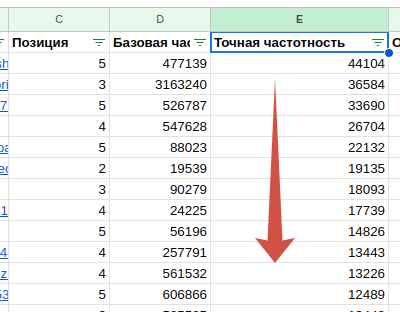
Затем отсортируйте по столбцу B «от А до Я». Запросы объединятся в группы, условные кластеры.
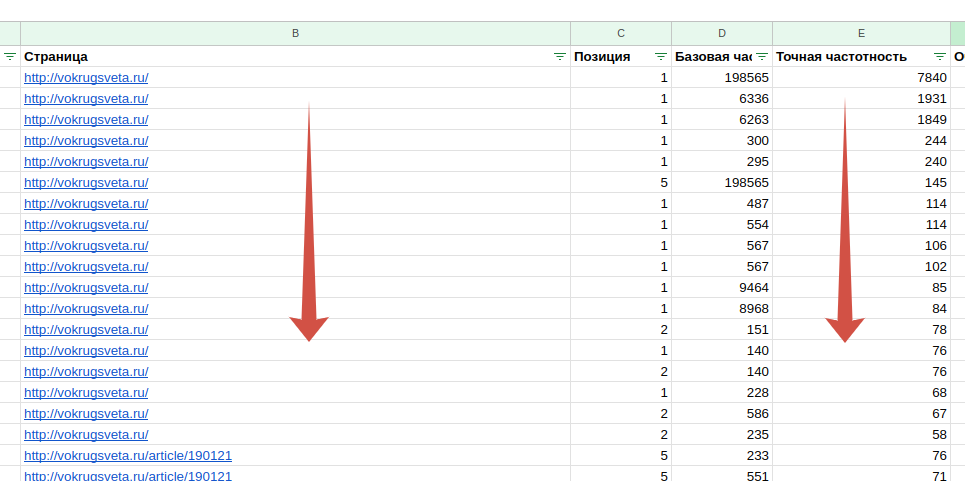
Теперь в каждой группе оставляем маркерный, то есть наиболее частотный запрос. Для этого жмем «Данные», затем «Очистка данных», затем «Удалить повторы».
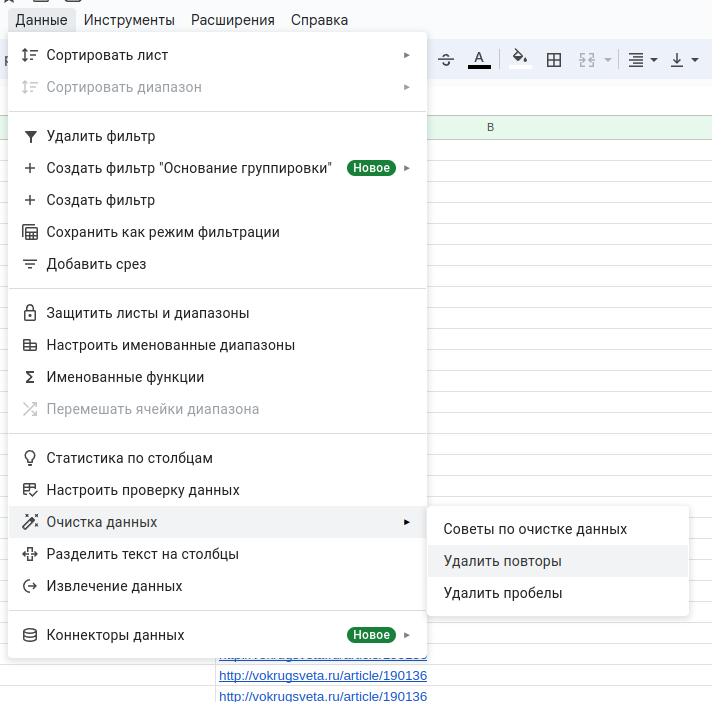
В открывшемся окне оставляем галочку только у столбца B.
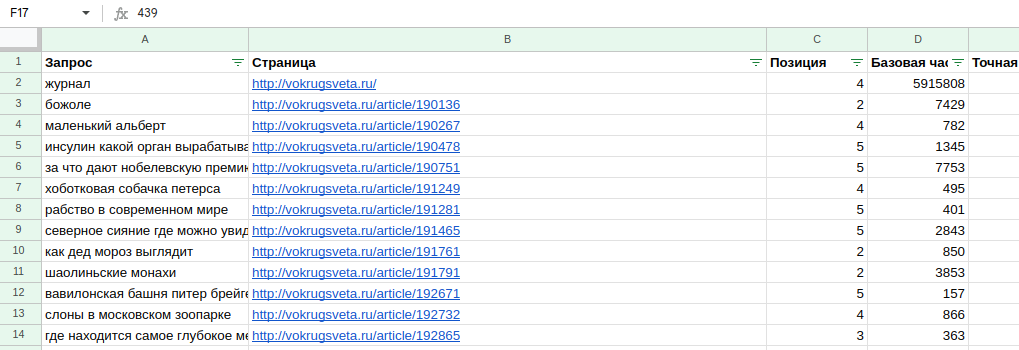
Половина дела за плечами, на каждую страницу сайта «Вокруг света» у нас осталось по одному наиболее частотному запросу.
3. Повторяем шаги №1 и №2 с запросами в «Гугле»
Чистим запросы из «Кейсо» с помощью фильтров, выгружаем csv, работаем с «Гугль Табличкой».
4. Объединяем два листа в один
Можно изначально склеить два csv и один раз удалить дубли, но мы делаем последовательно, чтобы сервис не зависал при больших объемах данных.
Повторяем шаг №2 и удаляем дубли. Если и в «Гугле», и в «Яндексе» в топе стоит одна и та же страница, то для нее останется только один запрос.
5. Удаляем низкочастотные запросы
Сортируем запросы по «Точной частотности». Анализировать четыре тысячи запросов — перебор, сократим до 2-3 тысяч. Можно было изначально отфильтровать частотность в «Кейсо», но тяжело предсказать, сколько строк исчезнет при чистке дублей.
Более того, если подходите к сбору семантики дотошно, полученные четыре тысячи разбейте на два блока и «проглотите» по частям.
Из таблицы удалим все запросы с точной частотностью ниже 100, для нашего клиента это всё равно слишком мелко.

6. Удаляем дубли и кластеризуем в «Кейсо»
Если удаляли дубли в шаге №2, то кластеризацию можно пропустить.
Возвращаемся в «Кейсо», идем в инструмент «Кластеризатор». Загружаем туда данные из столбца А, то есть сами запросы.
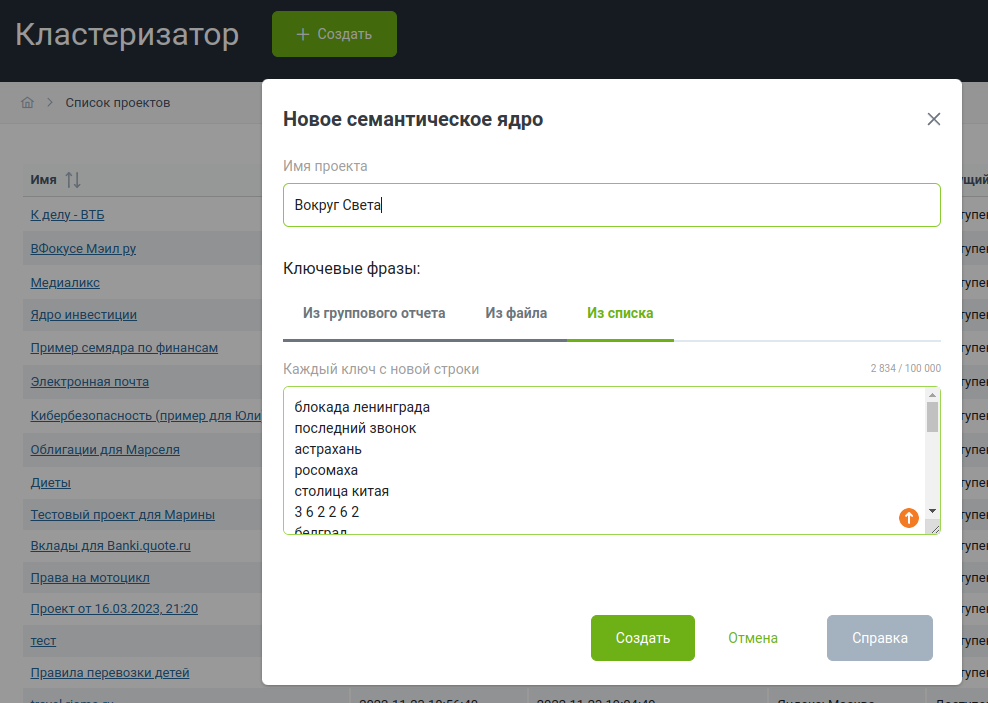
Используем инструмент «Удалить нечеткие дубли».
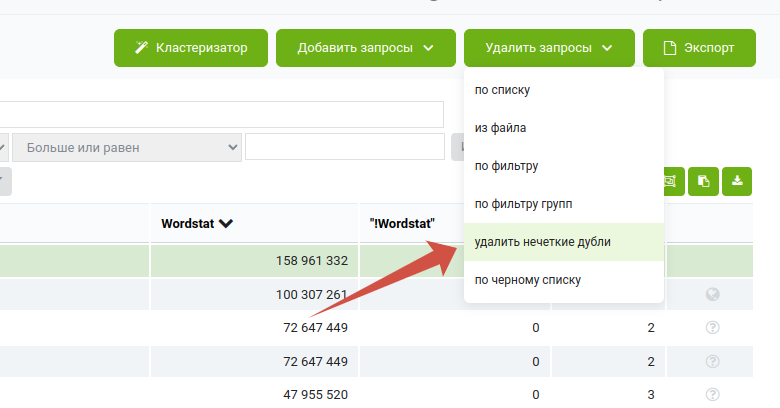
Если хотите полностью все изучить, не кластеризуйте запросы, либо разбивайте на меньшие группы. Если хочется наоборот, упростить задачу и пройтись «по верхам» — собирайте более общие кластеры.
Из почти трех тысяч запросов выделено всего 46 кластеров. Если не выполнять шаг №2, то эффект будет на порядок выше.
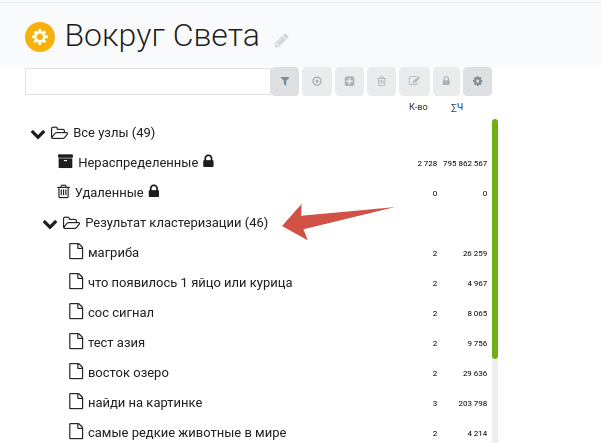
Итоговый результат выгружаем в csv «формата Б».
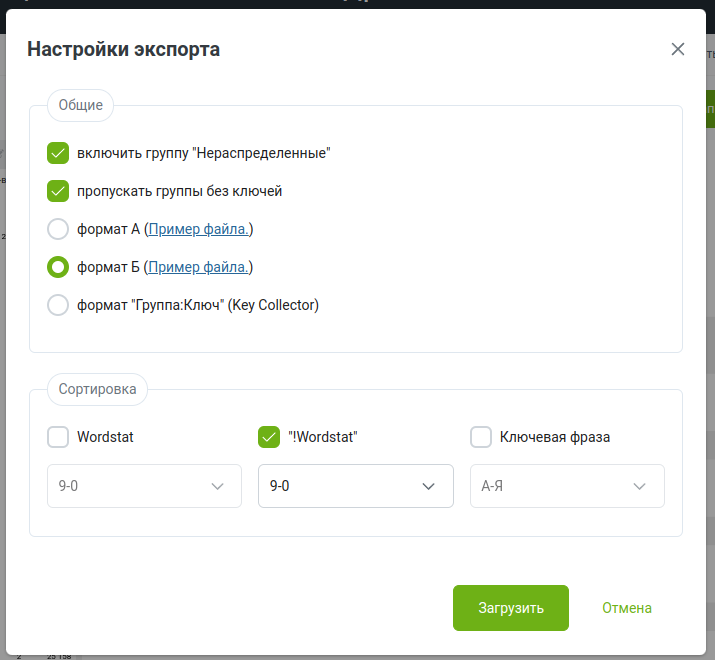
Импортируйте csv в табличку и по аналогии с шагом №2 удалите дубли по столбцу B, но перед этим перенесите всю «Нераспределенные» на отдельный лист.
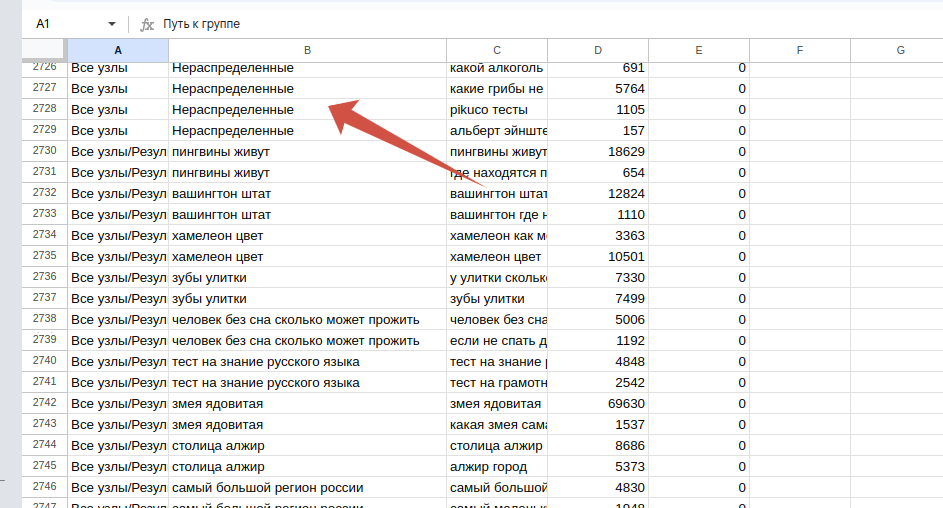
После удаления дублей на каждый кластер у нас останется по одному наиболее частотному запросу.
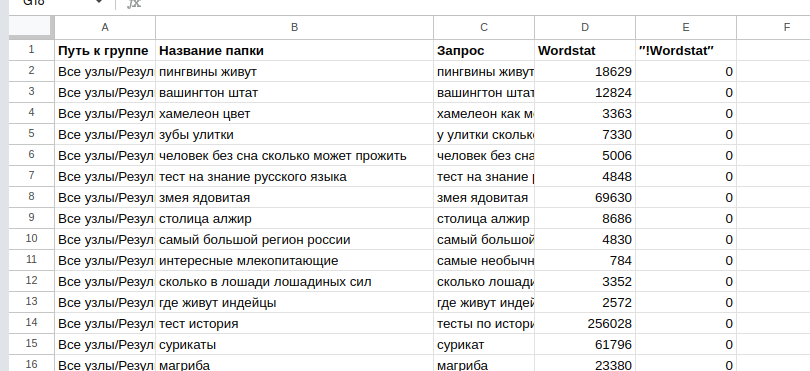
Объединяем два листа.
7. Проверяем частотность по «Арсёнкину»
Необязательный шаг. В целом частотность «Кейсо» подходит для первичного анализа, но так как мы привыкли работать с «ws», давайте пересоберем через инструмент «Яндекс Вордстат».
- Тип: «Сбор частотности»
- Регион: «Россия»
- Сбор частотности: «ключевая фраза»
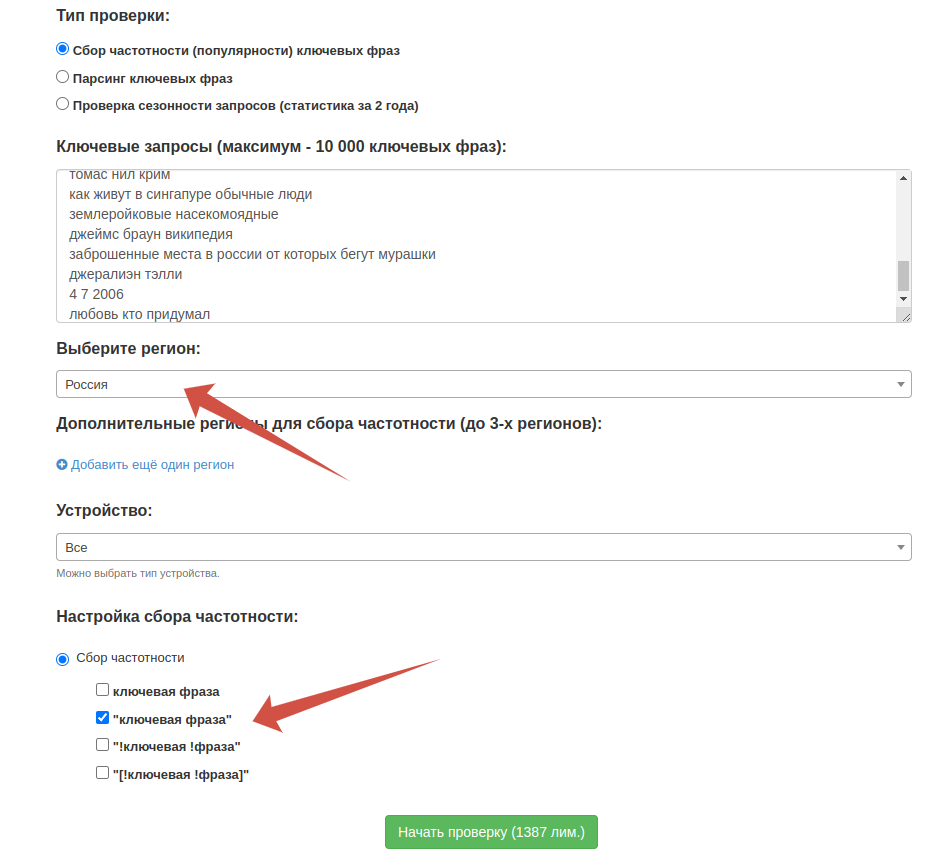
Проверка займет время, по итогу скачиваем файл xlsx и добавляем нужный столбец в «Гугль Таблицу». Сортируем облачную табличку по прямой частотности и удаляем слабые запросы.

8. Проверяем выдачу по «Арсёнкину»
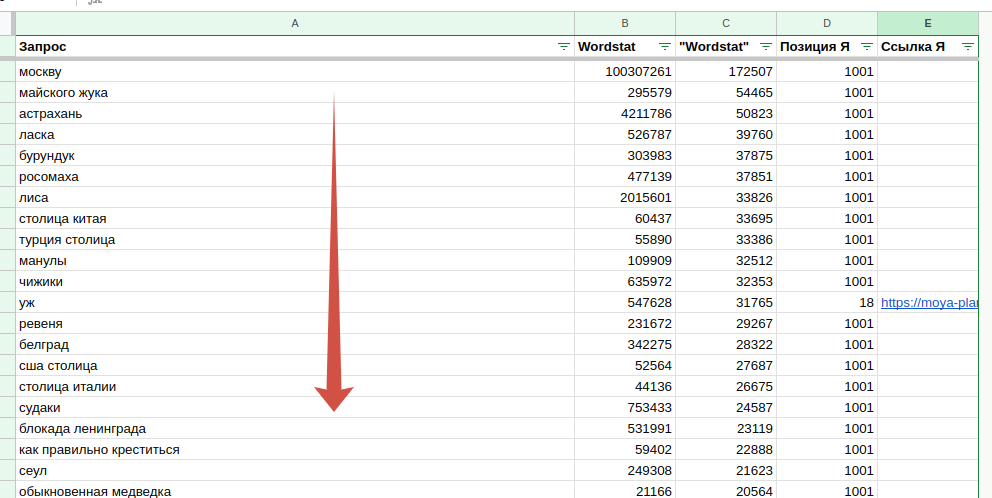
Массово проверим все запросы по выдаче, чтобы понять — не отписала ли редакция уже текст по этой теме. Воспользуемся инструментом «Проверка позиций». Есть ограничение: не более 1000 запросов за раз, поэтому разобьем изначальный список на три части.

Допустим, мы делаем контент-план для сайта телеканала «Моя планета». Вводим адрес, прожимаем галочку «Учитывать поддомены».
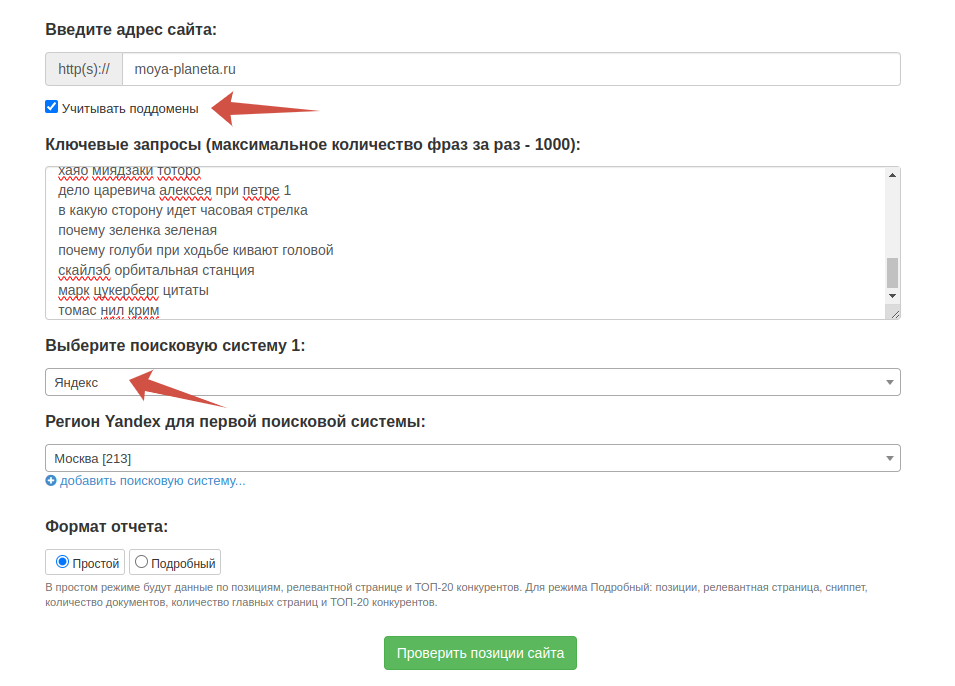
Для экономии лимитов достаточно одной поисковой системы. Ждем итоговый результат, скачиваем csv, импортируем на отдельный лист и добавляем нужные столбцы в нашу табличку. Сортируем по возрастанию позиций.
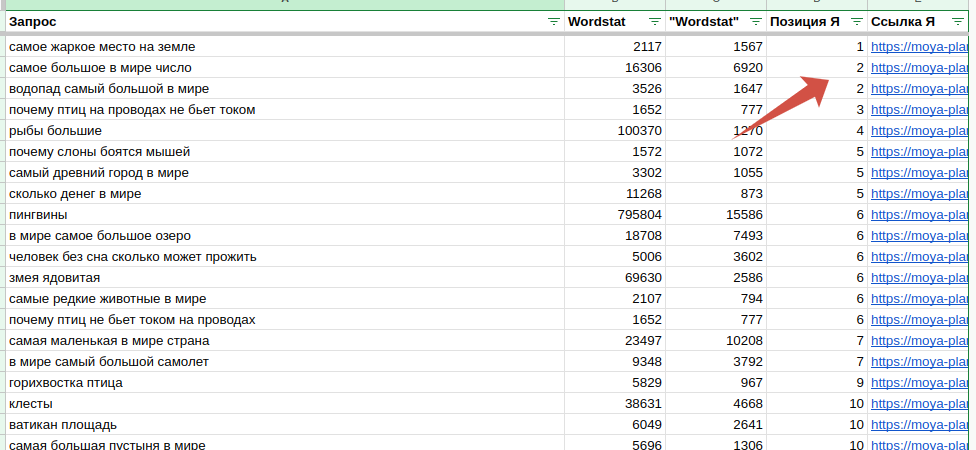
Смело можно удалять запросы, где клиент с первой по пятую позиции. Далее уже лучше не трогать — это будут кандидаты на обновление.
На этом всё, возвращаем сортировку по прямой частотности и уже вручную прорабатываем запросы для контент-плана.