Задача: собрать семантику раздела сайта-конкурента.
Проблема: не за что зацепиться в сетевом адресе страниц (нет «рубрики» /category/ в url).
Например, нас интересует «Финансовый журнал» сайта «Финам.ру». Всё, что у нас есть, это страница рубрики: https://www.finam.ru/publications/section/journal/.
Анализировать этот сайт «в лоб» не очень удобно, так как публикации внутри раздела никак не отличаются от тысяч новостей и статей в других категориях: https://www.finam.ru/publications/item/kak-rabotaet-venchurnoe-investirovanie-20241213-1440/
Если отправиться в «Кейсо» или «Мутаген», либо закопаешься, либо фильтрами отрежешь слишком сильно. В таких случаях помогает «ручной парсинг», когда мы непосредственно забираем ссылки со страницы.
Используем плагин View Rendered Source
Устанавливаем в браузер View Rendered Source. Можно и без него, но так удобнее: плюс привыкните к плагину, который очень полезен в техническом SEO.
После загрузки страницы нажмите на иконку View Rendered Source. Там будет три колонки: слева код, который пришел с сервера, посередине — что исполнил ваш браузер, справа — различия между двумя версиями.
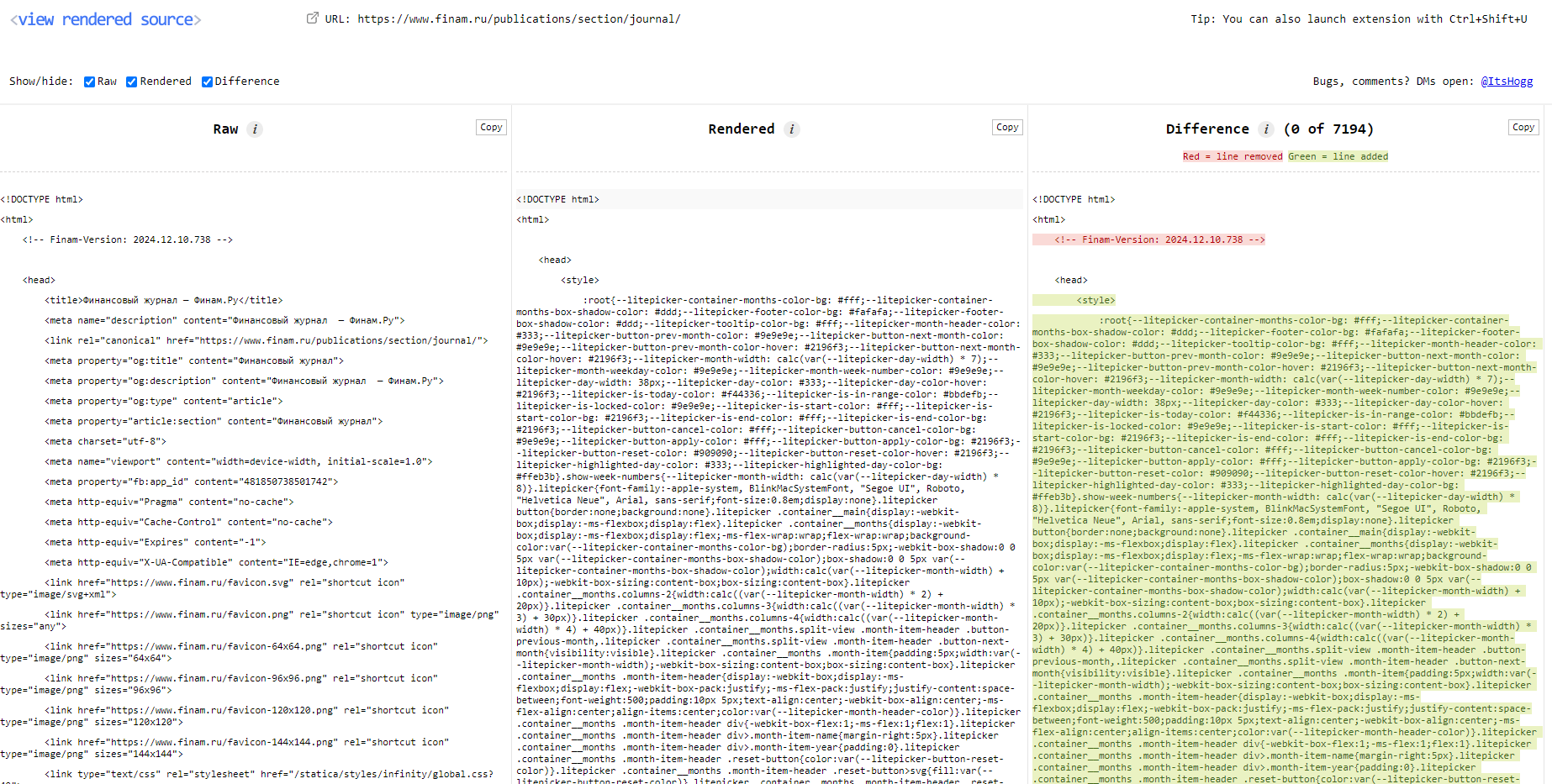
Теперь немного теории. На странице «Финансового журнала» по умолчанию отображаются лишь несколько десятков карточек, именно они отдаются с сервера. Но нам нужно больше!
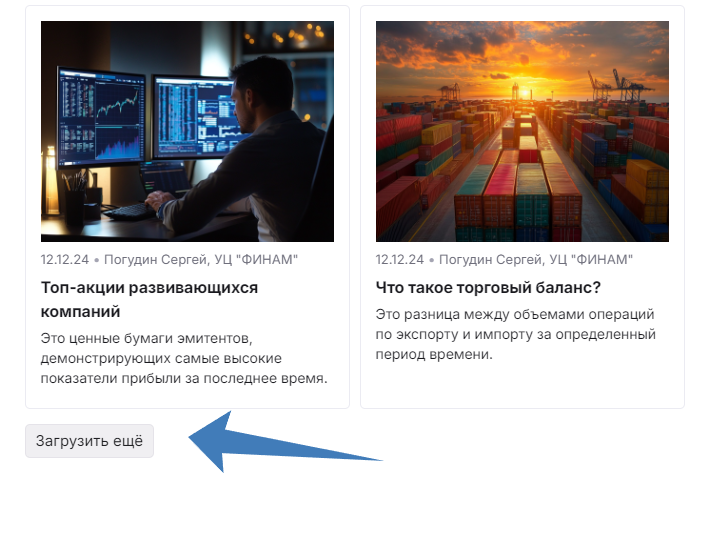
Если несколько раз нажать «Загрузить еще», на странице отобразится всё больше карточек. Но ссылки на эти статьи будут в коде, который исполнил браузер, а не отдал сервер. То есть во второй колонке плагина View Rendered Source.
Общая идея «ручного парсинга» в том, чтобы вывести на одной странице все-все-все материалы, скопировать полученный код и вытащить из него необходимые ссылки.
Нажмите кнопку 2-3 раза для примера, затем запустите плагин и скопируйте код из центральной колонки.
Вытаскиваем ссылки через Links Extractor
Переходим на сайт Links Extractor. Подобных сервисов много, если что — поищите в «Яндексе».
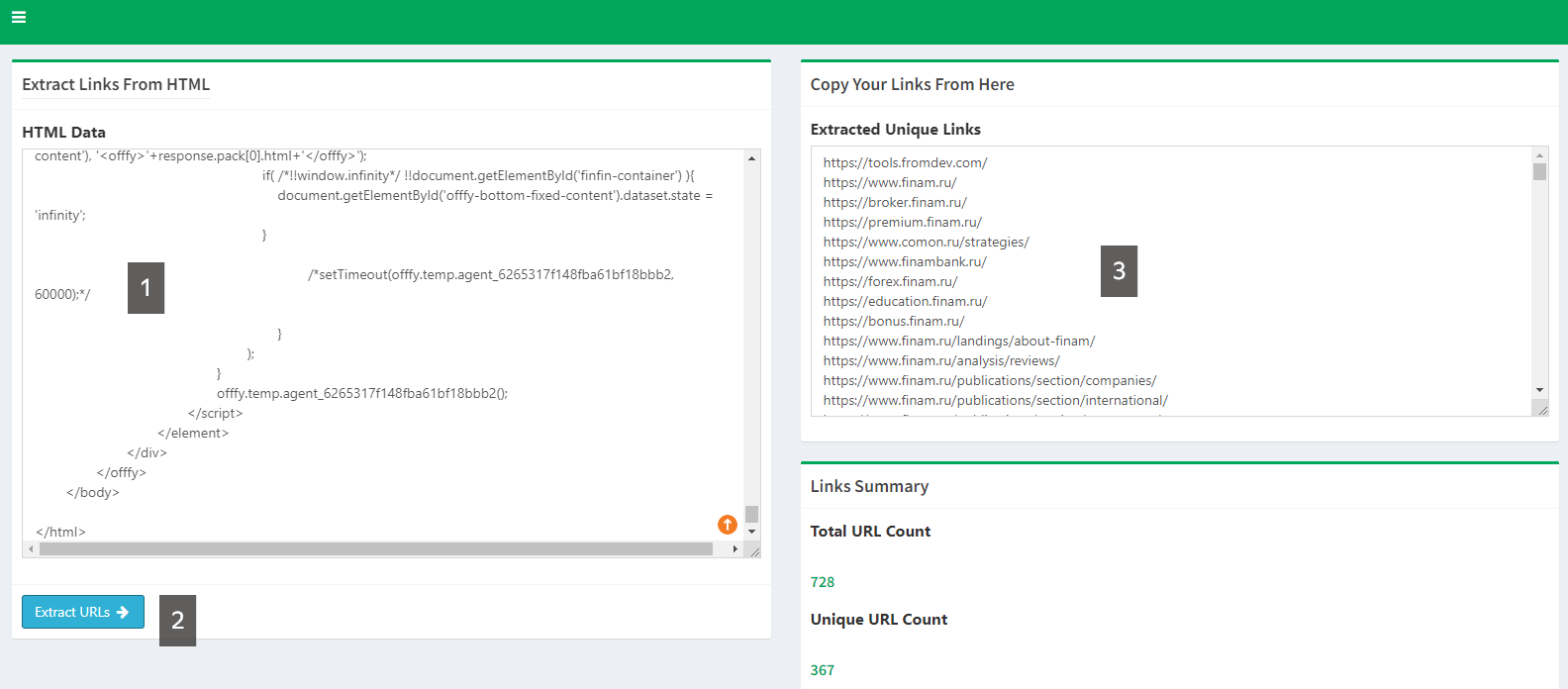
Ссылки будут со всей страницы, включая навигационное меню. Чтобы убрать лишнее, запомните, какой материал на странице первый, какой последний. В нашем случае интересен сетевой адрес, заканчивающийся на 20241213-1440.
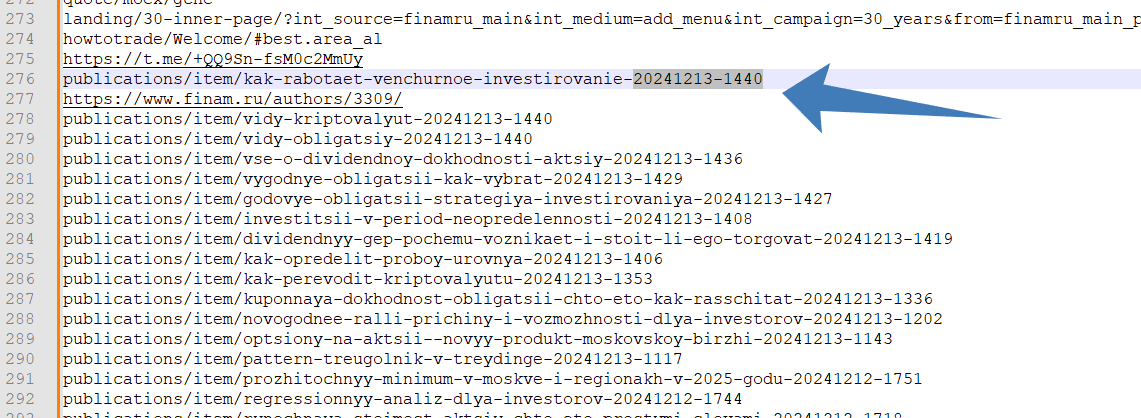
Дорабатываем список в таблице с помощью ВПР (VLOOKUP)
Ссылки выгрузились относительные, воспользуемся табличной формулой: ="https://www.finam.ru/"&A1.
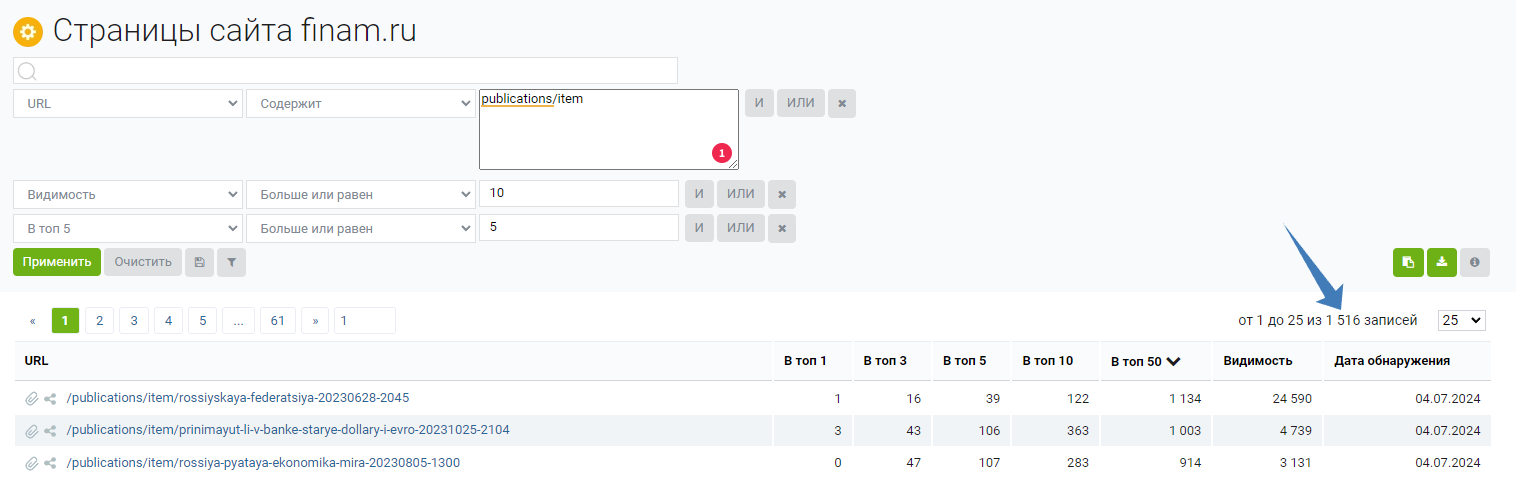
Остается два вопроса. Первый — что делать с адресами? Можно проработать их вручную, если мы понимаем, что качество работы SEO-команды на той стороне по этому разделу окупит время. Альтернативно выгружаем из «Кейсо» постраничный анализ сайта и сопоставляем какой-то параметр с урлами из нашего списка.
Грубо говоря, «Кейсо» или «Мутаген» обладают информацией обо всех страницах сайта «Финам». Мы же с помощью формулы =ВПР (=VLOOKUP в «Гугль Таблицах») уточним данные только по интересующим урлам.
Открываем csv в «Гугль Таблицах». При настройке =VLOOKUP возникла проблема: по умолчанию из «Кейсо» адреса выгрузились с протоколом http и без www, но это легко исправить.
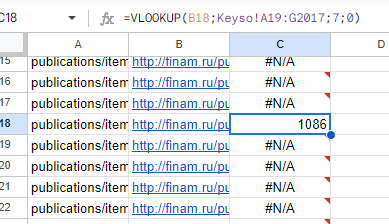
В примере выше мы выводим «Видимость». Как работает =ВПР (=VLOOKUP) прочтите в отдельной статье документации «Гугль Таблиц».
Второй вопрос: а как получить полный список статей в рубрике? В теории надо нажимать кнопку «Показать еще» сотню и более раз 🙂 Конечно, мы так делать не будем и для полного анализа «Финансового журнала» такой метод не подойдет, но общий принцип должен быть понятен.