Разберем, как можно подглядеть у конкурента темы для SEO-статей, если он использует дату в сетевых адресах.
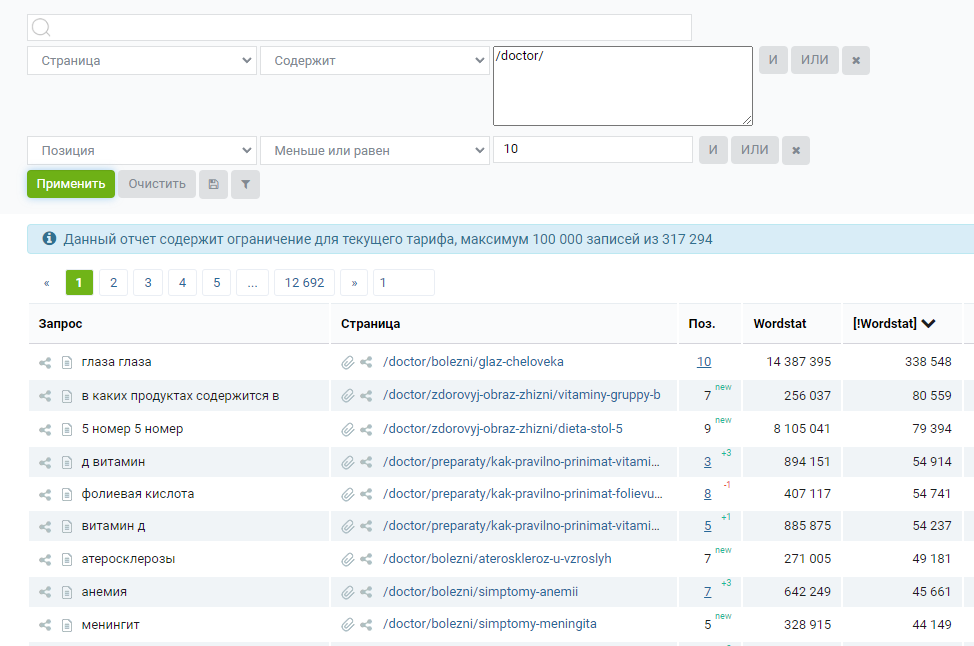
Удобно анализировать сайты, где тематики распределены по рубрикам. Например, хотим что-то из медицины и здоровья — идем в «Кейс Со» и изучаем запросы по разделу https://www.kp.ru/doctor/.
А вот с «РИА Новости» такой фокус не пройдет. Например, статья про пользу кофе опубликована без подпапки: https://ria.ru/20210217/kofe-1597909868.html.

И хотя вычленить материалы про здоровье с «РИА Новостей» без дополнительных усилий не получится, в целом проанализировать SEO-контент крупнейшего российского интернет-СМИ будет легко. Мы видим, что статья про пользу кофе лежит в папке за 17 февраля 2021 года: /20210217. Так давайте проверим, что еще интересного коллеги написали в этом месяце?
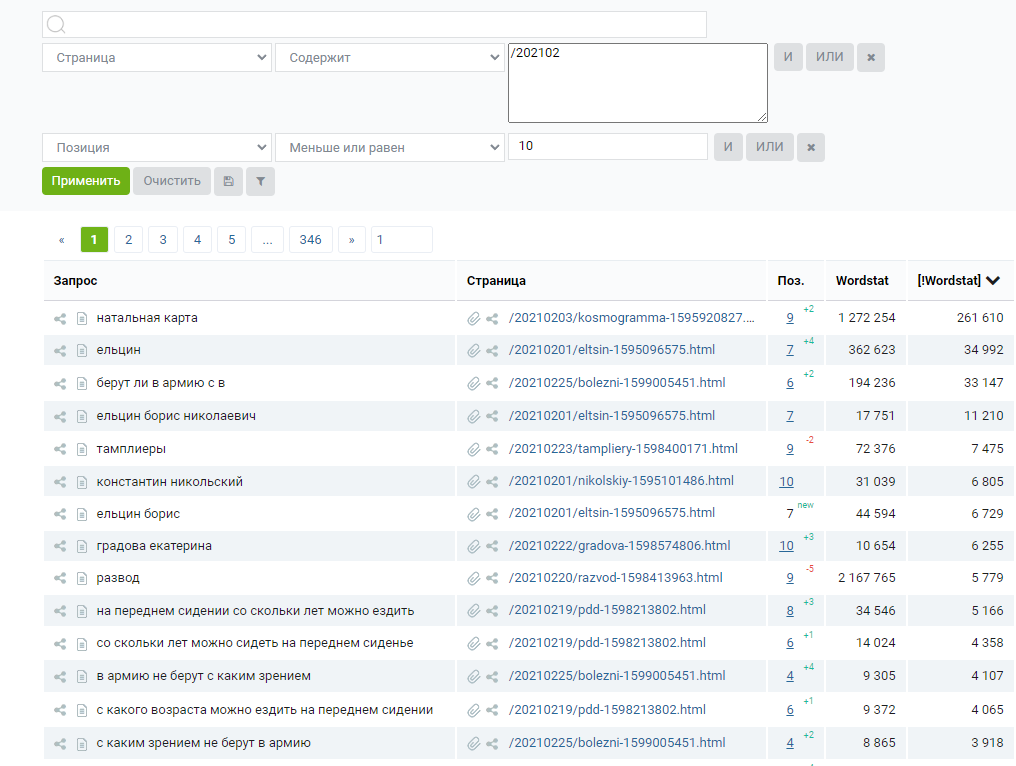
Неплохо, сразу видим SEO-статьи про «как подать на развод», «правила перевозки детей», «список болезней для армии». Однако иногда в таких запросах мешаются новостные материалы, которые по какой-то причине вылезли в топ по ВЧ-запросу. Особенно часто такое случается, если анализируете архив не двухгодичной давности, а что-то более свежее.
Тут нам поможет альтернативный отчет по страницам-лидерам. Едва ли небольшой материал ранжируется по сотням и тысячам запросов и обладает большой видимостью, так что можно вручную пройтись по тому и найти интересное.
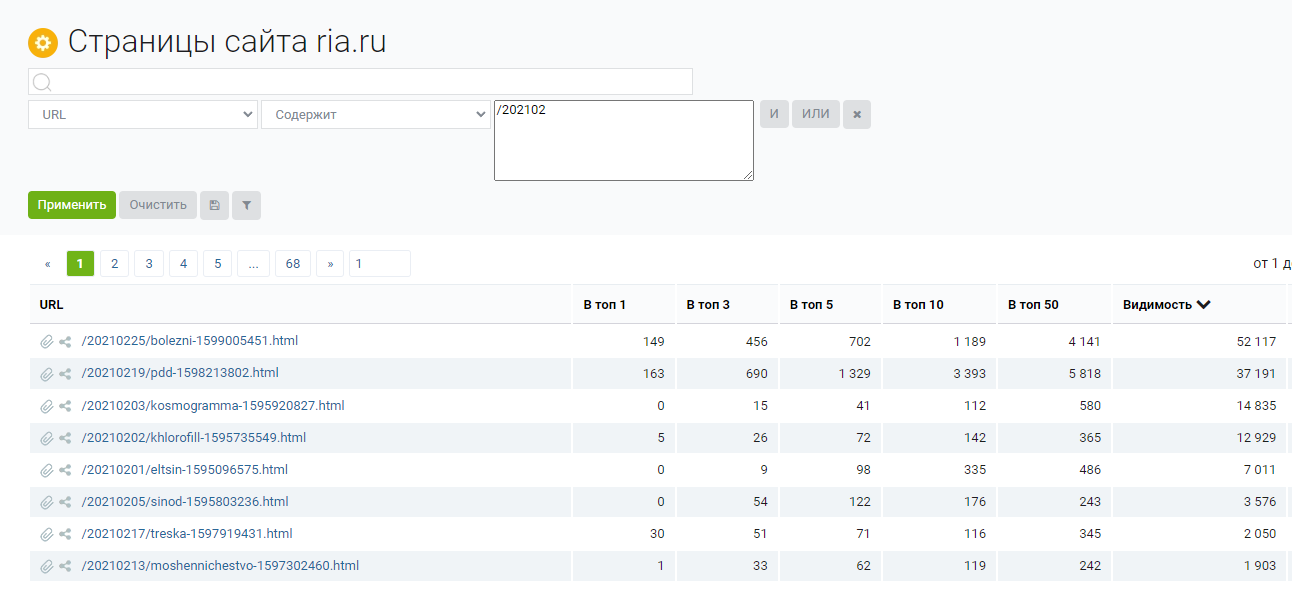
Видим те же «болезни» и «ПДД»; иногда в таком виде анализировать конкурента удобнее.
Способ работает не только с «РИА Новости». Хотя в примере «Известий» надо учесть, что основной SEO-контент у них публикуется в разделе без дат, но за то с авторами (например, https://iz.ru/1620678/dmitrii-migunov/kliuchevaia-stavka-tcb-rf-prognoz-na-2024-god-i-vliianie-na-zhizn-rossiian).
