Инструкция для начинающих специалистов поисковой оптимизации по формуле =IMPORTXML, и бонусный способ через «Инструменты Арсёнкина».
Представим, что у нас задача: проанализировать 30 материалов, которые другой специалист выгрузил из «Метрики». Прокликивать вручную каждый утомительно, лучше сэкономить немного времени и автоматически подтянуть значение тега <title> в таблицу.
Функция IMPORTXML
IMPORTXML отправляет бота по адресу, который вы выберете, и просит выгрузить определенную часть html-кода страницы. Разберем прямолинейное решение задачи: =IMPORTXML(A3;"//title").
"//title" — это xpath-запрос. С помощью этого языка запросов можно вытаскивать с веб-страниц различную информацию, но умение с ним работать — отдельный вопрос.
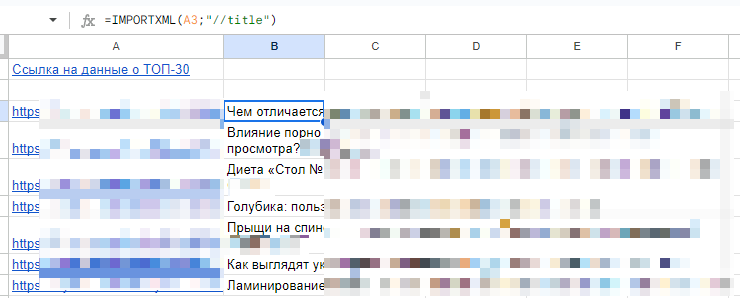
Как только вы добавите формулу впервые, «Таблицы» запросят разрешение погулять в интернете.
Далее аккуратно растяните формулу по списку: задача решена. Однако не рекомендуем делать это массово и поспешно, так как «Гугль» не любит, когда его так откровенно используют.
Правильнее растягивать по чуть-чуть, не более 20-30 строк за раз, и даже удалять формулу после того, как данные выгружены, сохраняя значение в виде текста. Впрочем, последний совет, возможно, не слишком эффективный, да и в последнее время «Гугль» ругается не слишком часто.
Если нарвались на отказ «Таблиц» выгружать данные, то либо повторите операцию на следующий день, либо используйте другой инструмент.
«Парсинг тегов title, description и H1-H6» в «Инструментах Арсёнкина»
В этой инструкции мы не рассматриваем использование программ-краулеров, будь то «Лягушка» или «СайтАналайзер». Для простого сбора <title> или <h1> проще использовать облачные сервисы, например, один из инструментов Александра Арсёнкина.
Выбираем вкладку «Список URL», загружаем все сетевые адреса и начинаем проверку.
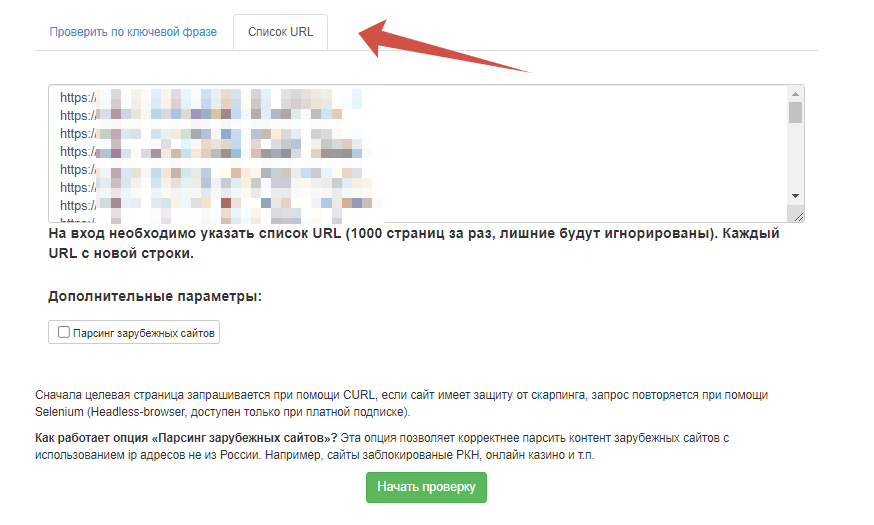
Преимущество этого способа в том, что «Арсёнкин» также выгрузит <h1>, description и всю структуру статьи по подзаголовкам.
